Software Security
Software Vulnerabilities
A common vulnerability that we are going to discuss is a buffer overflow.
A buffer overflow occurs when the amount of memory allocated for a piece of expected data is insufficient (too small) to hold the actual received data. As a result, the received data "runs over" into adjacent memory, often corrupting the values present there.
Specifically, stack buffer overflows are buffer overflows that exploit data in the call stack.
During program execution, a [stack](https://en.wikipedia.org/wiki/Stack_(abstract_data_type)) data structure, known as the call stack, is maintained. The call stack is made up of stack frames.
When a function is called, a stack frame is pushed onto the stack. When the function returns, the stack frame is popped off of the stack.
The stack frame contains the allocation of memory for the local variables defined by the function and the parameters passed into the function.
A function call involves a transfer of control from the calling function to the called function. Once the called function has completed its work, it needs to pass control back to the calling function. It does this by holding a reference to the return address, also present in the stack frame.
Stack buffer overflows can be exploited through normal system entry points that are called legitimately by non-malicious users of the system. By passing in carefully crafted data, however, an attacker can trigger a stack buffer overflow, and potentially gain control over the system's execution.
Vulnerable Program
The following program - which roughly resembles a standard password checking program - is vulnerable.
#include <stdio.h>
#include <strings.h>
int main(int argc, char *argv[]) {
int allow_login = 0;
char pwdstr[12];
char targetpwd[12] = "MyPwd123";
gets(pwdstr);
if(strncmp(pwdstr, targtpwd, 12) == 0)
allow_login = 1;
if(allow_login == 0)
printf("Login request rejected");
else
printf("Login request allowed");
}We have allocated space for int named allow_login that is initially set to 0.
In addition, we have allocated space for a user-submitted password (pwdstr) and a target password (targetpwd).
We then ask the user for their password (gets). Their response gets read into pwdstr and if pwdstr matches targetpwd (via strncmp), we set allow_login to 1.
Finally, if allow_login is 0, we print "Login request rejected". Otherwise, we print "Login request allowed".
Stack Access Quiz

Stack Access Quiz Solution

Since allow_login, pwdstr and targetpwd are all local variables to main, any access of them will access memory locations inside the stack frame for main.
The only lines of code that don't access the stack frame for main are the calls to printf, (which create a new stack frame), and else.
Understanding the Stack
There are two things you can do with a stack: push and pop.
The stack grows when something is pushed onto it, and shrinks when something is popped off of it.
The current "top" of the stack is maintained by a stack pointer, which points to different memory locations as the stack grows and shrinks.
We can assume that the stack grows from high (numerically larger) addresses to low (numerically smaller) addresses.
This means that the stack pointer points to the highest memory address at the beginning of program execution, and decreases as frames are pushed onto the stack.
Attacker Code Quiz

Attacker Code Quiz Solution

Remember that the stack pointer moves down in memory as space is allocated. This means that allow_login will receive memory starting at the highest feasible address, and pwdstr will receive memory starting at the next highest feasible address.
Suppose both int and char occupy 1 byte. allow_login may be allocated 1 byte of space starting at memory address 1000. pwdstr may be allocated 12 bytes of space starting at memory address 988.
If the user enters a password longer than 12 bytes, the remaining bytes will overflow into the memory allocated to allow_login, effectively overwriting its value.
Since login will succeed if allow_login is anything but 0 (i.e. not a fail-safe default), this overflow will almost certainly lead to access being granted.
Attacker Code Execution Part 1
If the attacker guesses the correct password and types that as input to the program, login will be allowed.
If the attacker guesses the wrong password - which fits into the allocated buffer - there will be no overflow and login will be rejected.
These are the two basic outcomes for a naive attack: either the attacker guesses correctly and access is granted or the attacker guesses incorrectly and access is denied.
Attacker Code Execution Part 2
In order to understand how an attacker can use buffer overflow to gain control of this program, we first need to look at how the data associated with this program is laid out on the stack.
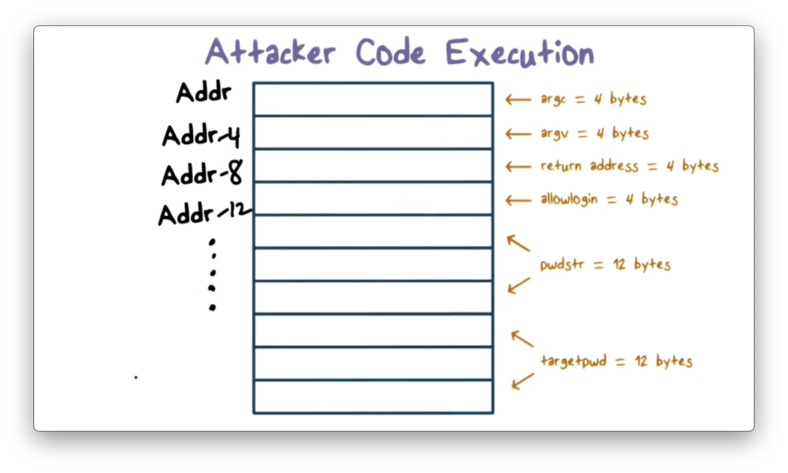
We know that the stack grows from higher memory addresses to lower memory address.
When we make the function call to main, we push the arguments argc (4 bytes) and argv (4 bytes) onto the stack.
Assuming the top of the stack is located at memory address addr, the stack pointer points to addr - 8 after pushing these argument onto the stack.
Next, we have to push the return address (4 bytes) onto the stack. Every time we make a function call, we have to push the return address onto the stack so the program knows where to continue execution within the calling function once the called function completes.
After pushing the return address, the stack pointer points to addr - 12.
Finally, we allocate space for allowLogin (4 bytes), pwdstr (12 bytes) and targetpwd (12 bytes).
If pwdstr is within 12 bytes, it will occupy only the memory allocated to it. If pwdstr is longer than 12 bytes, it will exhaust the 12 bytes allocated to it, and will overflow into the space allocated for allowLogin.
The reason pwdstr overflows into allowLogin and not targetPwd is because occupation of memory occurs sequentially, from lower memory addresses to higher memory address. Note: this is the opposite of the direction in which the stack grows.
If the supplied value for pwdstr is greater than 16 bytes, pwdstr will also overwrite the return address.
Attacker Code Execution Part 3
As an attacker, we want to direct program control to some location where the attacker can craft some code.
If the attacker writes more than 16 bytes to pwdstr, the buffer allocated to pwdstr will overflow and will overwrite the return address.
If we know the address of the code that we want to execute, we can craft our input carefully, such that the existing return address gets overwritten with the address we want.
If we do this, what will happen?
Remember, the point of the return address is to give the function a location to transfer control to when it is done executing. If we overwrite that address, the function will "return" to the address we supply and begin executing instructions from that address.
Buffer Overflow Quiz

Buffer Overflow Quiz Solution

The first answer is wrong. The target password can be as long as you'd like, but if the attacker submits a longer password, the overflow will still happen.
The third answer is also wrong. Besides the fact that you shouldn't ever really add useless variables, these variables will only provide a finite amount of distance between the user-filled buffer and the return address. With a long enough password, the attacker can still overwrite the return address.
Only the second answer is correct. The overflow happens precisely because input larger than the space allocated for that input is not rejected by the program.
Shellcode
The code that the attacker typically wants to craft is code that is going to launch a [command shell](https://en.wikipedia.org/wiki/Shell_(computing)). This type of code is called shellcode.
The execution of the shellcode creates a shell which allows the attacker to execute arbitrary commands.
You can write the shellcode in C, like this:
The "magic" here is execve, which replaces the currently running program with the invoked program - in this case, the shell at /bin/sh.
While the code can be written in C, it must be supplied to the vulnerable program as compiled machine code, because it is going to be stored in memory as actual machine instructions that will be executed once control is transferred.
Shellcode Privileges
The vulnerable program is running with some set of privileges before transfer is controlled to the shellcode.
When control is transferred, what privileges will be used?
The shellcode will have the same privileges as the host program.
This can be a set of privileges associated with a certain user and/or group. Alternatively, if the host program is a system service, the shellcode may end up with root privileges, essentially being handed the "keys to the the kingdom".
This is the best case scenario for the attacker, and the worst case scenario for the host.
NVD Quiz

NVD Quiz Solution

Return to libc
So far we have talked about stack buffer overflows. There are other variations of buffer overflows.
The first variation is called return-to-libc.
When we talked about shellcode, the goal was to overflow the return address to point to the location of our shellcode, but we don't need to return to code that we have explicitly written.
In return-to-libc, the return address will be modified to point to a standard library function. Of course, this assumes that you will be able to figure out the address of the library function.
If you return to the right kind of library function and you are able to set up the arguments for it on the stack, then you can execute any library function any parameters.
For example, if you point to the address of the system library function, and pass something like /bin/sh, you should be able to open a command shell.
The main idea with return-to-libc is that we have driven our exploit through instructions already present on the system, as opposed to supplying our own.
Heap Overflows
An overflow doesn't have to occur to memory associated with the stack. A heap overflow describes buffer overflows that occur in the heap.
One crucial difference between the heap and the stack is that the heap does not have a return address, so the traditional stack overflow / return-to-libc mechanism won't work.
What we have in the heap are function pointers, which can be overwritten to point to functions that we want to execute.
Heap overflows require more sophistication and more work than stack overflows.
OpenSSL Heartbleed
So far, when we have talked about buffer overflow, we have talked about writing data; specially, inputing data into some part of memory and overflowing the memory that was allocated to us.
Overflows don't just have to be associated with writing data. For example, if a variable has 12 bytes, but we ask to read 100 bytes, the read will continue past the original 12 bytes and return data in subsequent memory locations.
The OpenSSL Heartbleed vulernability did just this. It read past an assumed boundary (due to insufficient bounds checking) and was exploited to steal some important information - like encryption keys - that resided in adjacent memory.
Defense Against Buffer Overflows
Naturally, we shouldn't write code with buffer overflow vulnerabilities, but if such code is out there deployed on systems, we need to find ways to defend against attacks that exploit these vulnerabilities.
For instance, choice of programming language is crucial. There are languages where buffer overflows are not possible.
These languages:
are strongly typed
perform automatic bounds checking
perform automatic memory management
Languages that have these features are referred to as "safe" languages and include languages like Java and C++.
Safe Languages
If we choose a "safe" language, buffer overflows become impossible due to the checks the language performs at runtime.
For example, instead of having to perform bounds checking explicitly, programmers can rest assured knowing that the language runtime will perform the check for them.
So, why don't we use these languages for everything?
One drawback for these languages is performance degradation. The extra runtime checks slow down the execution of your program.
Unsafe Languages
When using "unsafe" languages, the programmer takes on the responsibility of preventing potential buffer overflow scenarios.
One way to do that is by checking all input to ensure that it conforms to expectations. Assume that all input is evil.
Another strategy to reduce the possibility of exploitation is to use safer functions that perform bounds checking for you. One such list of safe replacements for common library functions in C can be found here.
A third strategy is to use automated tools that analyze a program and flag any code that looks vulnerable.
These tools look for code patterns or unsafe functions and warn you which code fragments may be vulnerable for exploitation.
One issue with automated analysis tools is that they may have many false positives (flagging something that is not an issue), and may even have false negatives (not flagging something that is an issue). No tool should replace thoughtful programming.
There is no excuse for writing code that is insecure!
Strongly Vs Weakly Typed Language Quiz

Strongly Vs Weakly Typed Language Quiz Solution

Analysis Tools
A number of source code analysis tools are available. These tools analyze the source code of your application, and can flag potentially unsafe constructs and/or function usage.
Companies will often incorporate the use of these tools into their software development lifecycle to ensure that all code headed for production is audited before being released.
If you are attempting to analyze code that you didn't write, you may not have the source code available, at which point source code analysis tools obviously won't be helpful.
Stack Canary
One of the tricks that hackers use is to override the return address on the stack to point to some other code they want to execute.
During the execution of a function, however, there is no reason for the return address to be modified; that is, there is no reason a function should change where it returns during the middle of its execution.
As a result, if we can detect that the return address has been modified, we can show that a buffer overflow is being exploited and handle execution appropriately, likely with process termination.
How can we detect if the return address has been modified? We can use a stack canary, or a value that we write to an address just before the return address in a stack frame. If an overflow is exploited to overwrite the return address, the canary value will be overwritten with it.
All the runtime has to do, then, is to check if the canary value has changed when a function completes execution. If so, it can be sure that there is a problem.
What is nice about this approach is that the programmer doesn't have to do anything: the compiler inserts these checks. Of course, this means that the code may have to be recompiled with a compiler that has these features, a step which may come with its own issues.
ASLR
There are also OS-/hardware-based solutions which can help to thwart the exploitation of buffer overflow vulnerabilities.
The first technique that many operating systems use is address space layout randomization (ASLR).
Remember that one key job of the attacker is to be able to understand/approximate how memory is laid out within the stack or, in the case of return-to-libc, within a process's address space.
ASLR randomizes how memory is laid out within a process to make it very hard for an attacker to predict, even roughly, where certain key data structures and/or libraries reside.
Many modern operating systems provide ASLR support.
Non-executable stack
In the classic stack buffer overflow attack, the attacker writes shellcode to the stack and then overwrites the return address to point to that shellcode, which is then executed.
There is no legitimate reason for programs to execute instructions that are stored on the stack. One way to block executing shellcode off the stack is to make the stack non-executable.
Many modern operating systems implement such executable-space protection.
Buffer Overflow Attacks Quiz

Buffer Overflow Attacks Quiz Solution

Stack canaries do prevent return-to-libc buffer overflow attacks, because stack canaries prevent return address overwriting. Without overwriting the return address, a function can only return to the function that called it.
ASLR does not protect against read-only buffer overflow exploits. ASLR only makes it harder to supply key addresses in write-based buffer overflow exploits.
Heartbleed cannot be avoided by using a non-executable stack. Heartbleed is a read-based buffer overflow exploit, and the attack did not involve injecting any machine instructions onto the stack.
Last updated