Random Variate Generation, Continued
Composition (OPTIONAL)
In this lesson, we will learn about the composition method. This technique only works for random variables that are themselves combinations or mixtures of random variables, but it works well when we can use it.
Composition
We use composition when working with a random variable that comes from a combination of two random variables and can be decomposed into its constituent parts.
Let's consider a concrete example. An airplane might be late leaving the gate for two reasons, air traffic delays and maintenance delays, and these two delays compose the overall delay time. Most of the time, the total delay is due to a small air traffic delay, while, less often, the total delay is due to a larger maintenance delay.
If we can break down the total delay into the component delays - air traffic and maintenance - and those components are easy to generate, we can produce an expression for the total delay that combines the individual pieces.
The goal is to generate a random variable with a cdf, $F(x)$, of the following form:
In plain English, we want to generate a random variable whose cdf is a linear combination of other, "easier" cdf's, the $F_j$'s. Note that $p_j > 0$ and the sum of all $p_j$'s equals one.
Again, the main idea here is that, instead of trying to generate one complicated random variable, we can generate a collection of simpler random variables, weight them accordingly, and then sum them to realize the single random variable.
Don't fixate on the upper limit being infinity in the summation expression. Infinity is just the theoretical upper limit. In our airplane example, the actual limit was 2.
Here's the algorithm that we will use. First, we generate a positive integer $J$ such that $P(J=j) = p_j$ for all $j$. Then, we return $X$ from cdf $F_J(x)$.
Proof
Let's look at a proof that $X$ has cdf $F(x)$. First, we know that the cdf of $X$, by definition, is $P(X \leq x)$. Additionally, by the law of total probability:
Now, we expressed $P(J=j)$ as $p_j$, and we know that $P(X \leq x|J=j)$ is equal to $F_j$. Therefore:
Example
Consider the Laplace distribution, with the following pdf and cdf:
Note that the pdf and cdf look similar to those for exponential random variables, except that $x$ is allowed to be less than zero and the exponential has a coefficient of one-half. We can think of this distribution as the exponential distribution reflected off the $y$-axis.
Let's decompose this $X$ into a "negative exponential" and regular exponential distributions:
If we multiply each CDF here by one-half and sum them together, we get a Laplace random variable:
Let's look at both cases. When $x < 0$:
When $x > 0$:
As we can see, the composed cdf matches the expected cdf, both for $x > 0$ and $x < 0$.
The cdf tells us that we generate $X$ from $F_1(x)$ half the time and from $F_2(x)$ the other half of the time. Correspondingly, we'll use inverse transform to solve $F_1(X) = e^X = U$ for $X$ half the time and we'll solve $F_2 = 1-e^{-X} = U$ for the other half. Consider:
Precisely, we transform our uniform into an exponential with probability one-half and a negative exponential with probability negative one-half.
Box-Muller Normal RVs
In this lesson, we will talk about the Box-Muller method, which is a special-case algorithm used to generate standard normal random variables.
Box-Muller Method
If $U_1, U_2$ are iid $\mathcal (0,1)$, then the following quantities are iid Nor(0,1):
Note that we must perform the trig calculations in radians! In degrees, $2\pi U$ is a very small quantity, and resulting $Z_1$ and $Z_2$ will not be iid Nor(0,1).
Interesting Corollaries
We've mentioned before that if we square a standard normal random variable, we get a chi-squared random variable with one degree of freedom. If we add $n$ chi-squared randoms, we get a chi-squared with $n$ degrees of freedom:
Meanwhile, let's consider the sum of $Z^2_1$ and $Z^2_2$ algebraically:
Remember from trig class the $\sin^2(x) + \cos^2(x) = 1$, so:
Remember also how we transform exponential random variables:
All this to say, we just demonstrated that $Z^2_1 + Z^2_2 \sim \text{Exp}(1/2)$. Furthermore, and more interestingly, we just proved that:
Let's look at another example. Suppose we take $Z_1/Z_2$. One standard normal divided by another is a Cauchy random variable, and also a t(1) random variable.
As an aside, we can see how Cauchy random variables take on such a wide range of values. Suppose the normal in the denominator is very close to zero, and the normal in the numerator is further from zero. In that case, the quotient can take on very large positive and negative values.
Moreover:
Thus, we've just proven that $\tan(2\pi U) \sim \text{Cauchy}$. Likewise, we can take $Z_1/Z_2$, which proves additionally that $\cot(2\pi U) \sim \text{Cauchy}$.
Furthermore:
Polar Method
We can also use the polar method to generate standard normals, and this method is slightly faster than Box-Muller.
First, we generate two uniforms, $U_1, U_2 \overset{\text{iid}}{\sim} \mathcal U(0,1)$. Next, let's perform the following transformation:
Finally, we use the acceptance-rejection method. If $W > 1$, we reject and return to sampling uniforms. Otherwise:
We accept $Z_i \leftarrow V_iY,i=1,2$. As it turns out, $Z_1$ and $Z_2$ are iid Nor(0,1). This method is slightly faster than Box-Muller because it avoids expensive trigonometric calculations.
Order Statistics and Other Stuff
In this lesson, we will talk about how to generate order statistics efficiently.
Order Statistics
Suppose that we have the iid observations, $X_1, X_2,...,X_n$ from some distribution with cdf $F(x)$. We are interested in generating a random variable, $Y$, such that $Y$ is the minimum of the $X_i$'s: $Y = \min{X_1,...,X_n}$. Since $Y$ is itself a random variable, let's call its cdf $G(y)$. Furthermore, since $Y$ refers to the smallest $X_i$, it's called the first order statistic.
To generate $Y$, we could generate $n$ $X_i$'s individually, which takes $n$ units of work. Could we generate $Y$ more efficiently, using just one $\mathcal U(0,1)$?
The answer is yes! Since the $X_i$'s are iid, we have:
In English, the cdf of $Y$ is $P(Y \leq y)$, which is equivalent to the complement: $1 - P(Y > y)$. Since $Y = \min_i X_i$, $G(y) = 1 - P(\min_i X_i > y)$.
Now, since the minimum $X_i$ is greater than $Y$, then all of the $X_i$'s must be greater than $Y$:
Since the $X_i$'s are iid, $P(X_i > y) = P(X_1 > y)$. Therefore:
Finally, note that $F(y) = X \leq y$. Therefore, $1 - F(y) = P(X > y)$, so:
At this point, we can use inverse transform to express $Y$ in terms of $U$:
Example
Suppose $X_1,...X_n \sim \text{Exp}(\lambda)$. Then:
So, $Y = \min_iX_i \sim \text{Exp}(n\lambda)$. If we apply inverse transform we get:
We can do the same kind of thing for $Z = \max_i X_i$. Let's try it! If $Z = \max_iX_i$, then we can express $H(z)$ as:
Now, since the maximum $X_i$ is less than or equal to $Z$, then all of the $X_i$'s must less than or equal to $Z$:
Since the $X_i$'s are iid, $P(X_i \leq z) = P(X_1 \leq z)$. Therefore:
Finally, note that $F(z) = X \leq z$. Therefore:
Suppose $X_1,...X_n \sim \text{Exp}(\lambda)$. Then:
Let's apply inverse transform:
Other Stuff
If $Z_1, Z_2,...,Z_n$ are iid Nor(0,1), then the sum of the squares of the $Z_i$'s is a chi-squared random variable with $n$ degrees of freedom:
If $Z \sim \text{Nor}(0,1)$, and $Y \sim \chi^2(n)$, and $X$ and $Y$ are independent, then:
Note that t(1) is the Cauchy distribution.
If $X \sim \chi^2(n)$, and $Y \sim \chi^2(m)$, and $X$ and $Y$ are independent, then:
If we want to generate random variables from continuous empirical distributions, we'll have to settle for the CONT function in Arena for now.
Multivariate Normal Distribution
In this lesson, we will look at the multivariate normal distribution. This distribution is very important, and people use it all the time to model observations that are correlated with one another.
Bivariate Normal Distribution
Consider a random vector $(X, Y)$. For example, we might draw $X$ from a distribution of heights and $Y$ from a distribution of weights. This vector has the bivariate normal distribution with means $\mu_X = E[X]$ and $\mu_Y = E[Y]$, variances $\sigma^2_X = \text{Var}(X)$ and $\sigma^2_Y = \text{Var}(Y)$, and correlation $\rho = \text{Corr}(X,Y)$ if it has the following joint pdf:
Note the following definitions for $z_X(x)$ and $z_Y(y)$, which are standardized versions of the corresponding variables:
Let's contrast this pdf with the univariate normal pdf:
The fractions in front of the exponential looks similar in both cases. In fact, we could argue that the fraction for the univariate case might look like this:
In this case, however, $\text{Corr}(X, X) = 1$, so the expression involving $\rho^2$ reduces to one. All this to say, the bivariate case expands on the univariate case by incorporating another $\sigma\sqrt{2\pi}$ term. Consider:
Now let's look at the expression inside the exponential. Consider again the exponential for the univariate case:
Again, we might argue that this expression contains a hidden term concerning $\rho$ that gets removed because the correlation of $X$ with itself is one:
If we look at the bivariate case again, we see something that looks similar. We retain the $-1/2$ coefficient and we square standardized versions of $X$ and $Y$, although the standardization part is hidden away in $z_X$ and $z_Y$:
As we said, we can model heights and weights of people as a bivariate normal random variable because those two observations are correlated with one another. In layman's terms: shorter people tend to be lighter, and taller people tend to be heavier.
For example, consider the following observations, taken from a bivariate normal distribution where both means are zero, both variances are one, and the correlation between the two variables is 0.9.
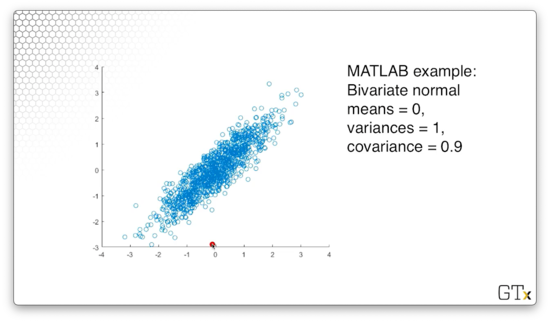
Multivariate Normal
The random vector $\bold X = (X1,...,X_k)^\top$ has the multivariate normal distribution with mean vector $\boldsymbol \mu = (\mu_1,...,\mu_k)^\top$ and $k \times k$ covariance matrix $\Sigma = (\sigma{ij})$, if it has the following pdf:
Notice that the vector $\bold X$ and the vector $\boldsymbol \mu$ have the same dimensions: random variable $X_i$ has the expected value $\mu_i$.
Now let's talk about the covariance matrix $\Sigma$. This matrix has $k$ rows and $k$ columns, and the cell at the $i$th row and $j$th column holds the covariance between $Xi$ and $X_j$. Of course, the cell at $\Sigma{ii}$ holds the covariance of $X_i$ with itself, which is just the variance of $X_i$.
Now let's look at the fraction in front of the exponential expression. Remember that, in one dimension, we took $\sqrt{2\pi}$. In $k$ dimensions, we take $2\pi^{k/2}$. In one dimension, we take $\sqrt{\sigma^2}$. In $k$ dimensions, we take the square root of the determinant of $\Sigma$, where the determinant is a generalization of the variance.
Now let's look at the exponential expression. In one dimension, we computed:
In $k$ dimensions, we compute:
Here, $(\bold x - \boldsymbol \mu)^\top(\bold x - \boldsymbol \mu)$ corresponds to $(x - \mu)^2$, and $\Sigma^{-1}$ is the inverse of the covariance matrix, which corresponds to $1/\sigma$ in the univariate case.
All this to say, the multivariate normal distribution generalizes the univariate normal distribution.
The multivariate case has the following properties:
We can express a random variable coming from this distribution with the following notation: $\bold X \sim \text{Nor}_k(\boldsymbol{\mu}, \Sigma)$.
Generating Multivariate Random Variables
To generate $\bold X$, let's start out with a vector of iid Nor(0,1) random variables in the same dimension as $\bold X$: $\bold Z = (Z_1,...,Z_k)$. We can express $Z$ as $\bold Z \sim \text{Nor}_k(\bold 0, I)$, where $\bold 0$ is a $k$-dimensional vector of zeroes and $I$ is the $k \times k$ identity matrix. Note that the identity matrix makes sense here: since the values are iid, everywhere but the diagonal is zero.
Now, suppose that we can find the lower triangular $k \times k$ Cholesky matrix $C$, such that $\Sigma = CC^\top$. We can think of this matrix, informally, as the "square root" of the covariance matrix.
It can be shown that $\bold X = \boldsymbol \mu + C \bold Z$ is multivariate normal with mean $\boldsymbol \mu$ and covariance matrix:
How do we find this magic matrix $C$? For $k = 2$, we can easily derive $C$:
Again, if we multiply $C$ by $C^\top$, we get the covariance matrix, $\Sigma$:
Here's how we generate $\bold X$. Since $\bold X = \boldsymbol \mu + C \bold Z$, if we carry the vector addition and matrix multiplication out, we have:
Here's the algorithm for computing a $k$-dimensional Cholesky matrix, $C$.

Once we compute $C$, we can easily generate the multivariate normal random variable $\bold X = \boldsymbol \mu + C \bold Z$. First, we generate $k$ iid Nor(0,1) uniforms, $Z_1, Z_2,...,Z_k$. Next, we set $X_i$ equal to the following expression:
Note that the sum we take above is nothing more than the sum of the standard normals multiplied by the $i$th row in $\Sigma$.
Finally, we return $\bold X = (X_1, X_2, X_k)$.
Baby Stochastic Processes (OPTIONAL)
In this lesson, we will talk about how we generate some easy stochastic processes: Markov chains and Poisson arrivals.
Markov Chains
A time series is a collection of observations ordered by time: day to day or minute to minute, for instance. We will look at a time series of daily weather observations and determine the probability of moving between two different states, sunny and rainy.
It could be the case that the days are not independent of one another; in other words, if we have thunderstorms today, there is likely a higher than average probability that we will have thunderstorms tomorrow.
Suppose it turns out the probability that we have a thunderstorm tomorrow only depends on whether we had a thunderstorm today, and nothing else. In that case, the sequence of weather outcomes is a type of stochastic process called a Markov chain.
Example
Let's let $X_i = 0$ if it rains on day $i$; otherwise, $X_i = 1$. Note that we aren't dealing with Bernoulli observations here because the trials are not independent; that is, the weather on day $i+1$ depends on the weather on day $i$.
We can denote the day-to-day transition probabilities with the following equation:
In other words, $P{jk}$ refers to the probability of experiencing state $X = k$ on day $i+1$, given that we experienced state $X = j$ on day $i$. For example, $P{01}$ refers to the probability that it is sunny tomorrow, given that it rained today.
Suppose that we know the various transition probabilities, and we have the following probability state matrix:
Remember that state zero is rain and state one is sun. Therefore, $P{00} = 0.7$ means that the probability that we have rain on day $i+1$ given that we had rain on day $i$ equals 0.7. Likewise, $P{01} = 0.3$ means that the probability that we have sun on day $i+1$ given that we had rain on day $i$ equals 0.3.
Notice that the probabilities add up to one across the rows, signifying that, for a given state on day $i$, the probability of moving to some state on day $i+1$ is one: the process must transition to a new state (of course, this new state could be equivalent to the current state).
Suppose it rains on Monday, and we want to simulate the rest of the week. We will fill out the following table:
Let's talk about the columns. Obviously, the first column refers to the day of the week. The column titled $P(\text{R} | X{i-1})$ refers to the probability of rain given yesterday's weather. Note that we also represent this probability with $P{\cdot 0}$, where the dot refers to yesterday's state.
In the third column, we sample a uniform. In the fourth column, we check whether that uniform is less than the transition probability from yesterday's state to rain. Finally, in the fifth column, we remark whether it rains, based on whether the uniform is less than or equal to the transition probability.
Let's see what happens on Tuesday:
Here, we are looking at the probability of transitioning from a rainy day to another rainy day. If we look up that particular probability in our state transition matrix, we get $P_{00} = 0.7$. Next, we sample a uniform, $U_i = 0.62$, and check whether that uniform is less than the transition probability. Since $0.62 < 0.7$, we say that it will rain on Tuesday.
Let's see what happens on Wednesday:
Similarly, we are looking at the probability of again transitioning from a rainy day to another rainy day, so our transition probability is still $P_{00} = 0.7$. We draw another uniform, $U_i = 0.03$, and, since $0.03 < 0.7$, we say that it will rain on Wednesday.
Let's see what happens on Thursday:
Here, we have the same transition probability as previously, but our uniform, $U_i = 0.77$, happens to be larger than our transition probability: $0.77 > 0.7$. As a result, we say that it will not rain on Thursday.
Finally, let's look at Friday:
On Friday, we have a new transition probability. This time, we are looking at the probability of rain given sun, and $P_{10} = 0.4$. Again we draw our uniform, which happens to be greater than the transition probability, so we say it will be sunny on Friday.
Poisson Arrivals
Let's suppose we have a Poisson($\lambda$) process with a constant arrival rate of $\lambda$. The interarrival times of such a process are iid Exp($\lambda$). Remember that, even though the rate is constant, the arrivals themselves are still random because the interarrival times are random.
Let's look at how we generate the arrival times. Note that we set $T_0 \leftarrow 0$ to initialize the process at time zero. From there, we can compute the $i$th arrival time, $T_i$, as:
In other words, the next arrival time equals the previous arrival time, plus an exponential random variable referring to the interarrival time. Even more basically, the time at which the next person shows up is equal to the time at which the last person showed up, plus some randomly generated interarrival time.
Note that, even though we seem to be subtracting from $T_{i-1}$, the natural log of $0 \leq U_i < 1$ is a negative number, so we are, in fact, adding two positive quantities here.
We refer to this iterative process as bootstrapping, whereby we build subsequent arrivals on previous arrivals.
Fixed Arrivals
Suppose we want to generate a fixed number, $n$, arrivals from a Poisson($\lambda$) process in a fixed time interval $[a,b]$. Of course, we cannot guarantee any number of arrivals in a fixed time interval in a Poisson process because the interarrival times are random.
It turns out that there is a theorem that states the following: the joint distribution of $n$ arrivals from the Poisson process during some interval $[a,b]$ is equivalent to the joint distribution of the order statistics of $n$ iid $\mathcal U(a,b)$ random variables.
Here's the algorithm. First, we generate $n$ iid $\mathcal U(0,1)$ uniforms, $U1,...,U_n$. Next, we sort them: $U{(1)} < U{(2)} < ... < U{(n)}$. Finally, we transform them to lie on the interval $[a,b]$:
Nonhomogeneous Poisson Processes
In this lesson, we will look at nonhomogeneous Poisson processes (NHPPs), where the arrival rate changes over time. We have to be careful here: we can't use the algorithm we discussed last time to generate arrivals from NHPPs.
NHPPs - Nonstationary Arrivals
An NHPP maintains the same assumptions as a standard Poisson process, except that the arrival rate, $\lambda$, isn't constant, so the stationary increments assumption no longer applies.
Let's define the function $\lambda(t)$, which describes the arrival rate at time $t$. Let's also define the function $N(t)$, which counts the number of arrivals during $[0,t]$.
Consider the following theorem to describe the number of arrivals from an NHPP between time $s$ and time $t$:
Example
Suppose that the arrival pattern to the Waffle House over a certain time period is an NHPP with $\lambda(t) = t^2$. Let's find the probability that there will be exactly four arrivals between times $t=1$ and $t=2$.
From the equation above, we can see that the number of arrivals in this time interval is:
Since the number of arrivals is $X \sim \text{Pois}(7/3)$, we can calculate the $P(X = 4)$ using the pmf, $f(x)$:
Incorrect NHPP Algorithm
Now, let's look at an incorrect algorithm for generating NHPP arrivals. This algorithm is particularly bad because it can "skip" intervals if $\lambda(t)$ grows very quickly.
Here's the algorithm.

We initialize the algorithm with $T_0 \leftarrow 0; i \leftarrow 0$. To generate the $i$th arrival, we first sample $U \sim \mathcal U(0,1)$, and then we perform the following computation:
Note that, instead of multiplying by $-1 / \lambda$, we multiply by $-1 / \lambda(T_i)$, which is the arrival rate at the time of the previous arrival. The problem arises when the arrival rate radically changes between the time we generate the new arrival and the time that arrival occurs.
Specifically, if $\lambda(T{i+1}) >> \lambda(T{i})$, then the arrival rate we use to generate arrival $T_{i+1}$, evaluated at time $T_i$, is too small. Since we capture the arrival rate of the next arrival at the time of the current arrival, we essentially consider the rate to be fixed between that time and the time the arrival actually occurs.
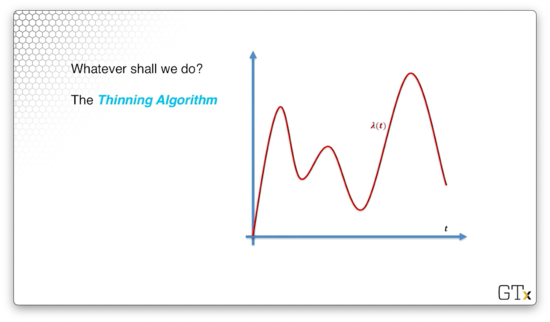
Thinning Algorithm
Consider the following rate function, $\lambda(t)$, graphed below. We can suppose, perhaps, that this function depicts the arrivals in a restaurant, and the peaks correspond to breakfast, lunch, and dinner rushes.
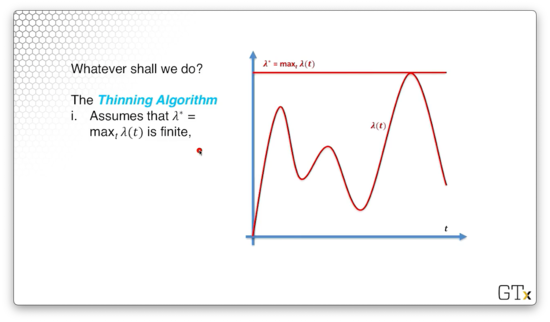
We are going to use the thinning algorithm to generate the $i$th arrival. First, we assume that $\lambda^ = \max_t\lambda(t)$ is finite. We can see the line $y = \lambda^$ drawn below.
From there, we will generate potential arrivals at that maximum rate $\lambda^*$:
We can see the potential arrivals in dotted purple below.

We will accept a potential arrival at time $t$ as a real arrival with probability $\lambda(t) / \lambda^$. Thus, as $\lambda(t)$ approaches $\lambda^$, the likelihood that we accept $t$ as a real arrival increases proportionally to $\lambda(t) / \lambda^*$. We call this algorithm the thinning algorithm because it thins out potential arrivals.
Let's look at the algorithm.

We initialize the algorithm $T_0 \leftarrow 0; i \leftarrow 0$. Next, we initialize $t \leftarrow T_i$, and then we iterate. We generate two iid Unif(0,1) random variables, $U$ and $V$, and then we generate a potential arrival:
We keep generating $U$ and $V$ until this condition holds:
In other words, we only keep the potential arrival with probability $\lambda(t)/\lambda^*$. After we accept $t$, we set $i$ to $i+1$, and $T_i$ to $t$, and repeat.
DEMO
In this demo, we will look at how to implement an NHPP in Excel.
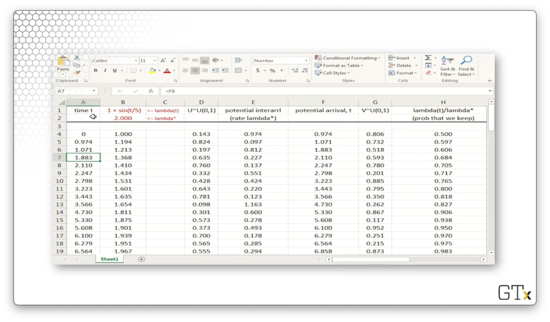
In column A, we have potential NHPP arrival times.
In column B, we have the rate function $\lambda(t) = 1 + \sin(t/5)$. Because the sine function is periodic, so are the arrival rates generated by $\lambda(t)$. In fact, $\lambda(t)$ never goes below zero, and never goes above two, so $\lambda^* = 2$.
In column D, we have a sequence of $U_i \sim \mathcal U(0,1)$ random variables, which we will use to generate interarrival times.
In column E, we generate the potential interarrival times by transforming $U_i$ into an Exp($\lambda^*$) random variable.
In column F, we bootstrap the arrivals, generating the $i$th arrival by adding the $i-1$th arrival and the $i$th interarrival time. Note that these potential arrivals are the same values in column A.
In column G, we generate another sequence of random variables $V_i \sim \mathcal U(0,1)$, which we will use to determine whether we accept the potential arrival as a real arrival.
In column H, we generate $\lambda(t)/\lambda^*$, which refers to the probability that we accept the corresponding potential arrival at time $t$.
If $V_i < \lambda(t_i)/\lambda^*$, then we accept the arrival, and we show this boolean value in column I.
In column J, we copy over the real arrival times for all potential arrivals where $V_i < \lambda(t_i)/\lambda^*$. Otherwise, we mark the cell as "FALSE".
Finally, in column K, we update the arrival rate for the next iteration.
Here's what the plot of arrival rates over time looks like for this NHPP. Every dot represents an accepted arrival. In the space between the dots, we may have generated potential arrivals, but we didn't accept them as real.

We can see that we have many real arrivals when the $\lambda(t)$ is close to $\lambda^$ and few real arrivals when the two values diverge. Of course, this observation makes sense, given that we accept potential arrivals with probability $\lambda(t) / \lambda^$.
Time Series (OPTIONAL)
In this lesson, we will look at various time series processes, most of which are used in forecasting. In particular, we will be looking at auto-regressive moving average processes (ARMA), which have standard-normal noise, and auto-regressive Pareto (ARP) processes, which have Pareto noise.
First-Order Moving Average Process
A first-order moving average process, or MA(1), is a popular time series for modeling and detecting trends. This process is defined as follows:
Here, $\theta$ is a constant, and the $\epsilon_i$ terms are typically iid Nor(0,1) - in practice, they can be iid anything - and they are independent of $Y_0$.
Notice that $Y1 = \epsilon_1 + \theta\epsilon_0$, and $Y_2 = \epsilon_2 + \theta\epsilon_1$. Both $Y_1$ and $Y_2$ contain an $\epsilon_1$ term; generally, $Y_i$ and $Y{i-1}$ pairs are correlated.
Let's derive the variance of $Y_i$. Remember, that:
Let's consider $Yi = \epsilon_i + \theta\epsilon{i-1}$:
Now, we know that successive $\epsilon_i$'s are independent, so the covariance is zero:
Furthermore, we know that $\text{Var}(aX) = a^2\text{Var}(X)$, so:
Finally, since the $\epsilon_i$'s are Nor(0,1), they both have variance one, leaving us with:
Now, let's look at the covariance between successive $Yi, Y{i+1}$ pairs. Here's a covariance property:
So:
Since the $\epsilon_i$'s are independent, we know that $\text{Cov}(\epsilon_i, \epsilon_j) = 0, i \neq j$. So:
We also know that $\text{Cov}(X,X) = \text{Var}(X)$, and, since $\epsilon_i \sim \text{Nor}(0,1)$, $\text{Var}(\epsilon_i) = 1$. So:
We can also demonstrate, using the above formula, that $\text{Cov}(Yi, Y{i+k}) = 0, k \geq 2$.
As we can see, the covariances die off pretty quickly. We probably wouldn't use an MA(1) process to model, say month-to-month unemployment, because the unemployment rate among three months is correlated, and this type of process cannot express that.
How might we generate an MA(1) process? Let's start with $\epsilon_0 \sim \text{Nor}(0,1)$. Then, we generate $\epsilon_1 \sim \text{Nor}(0,1)$ to get $Y_1$, $\epsilon_2 \sim \text{Nor}(0,1)$ to get $Y_2$, and so on. Every time we generate a new $\epsilon_i$, we can compute the corresponding $Y_i$.
First-Order Autoregressive Process
Now let's look at a first-order autoregressive process, or AR(1), which is used to model many different real-world processes. The AR(1) process is defined as:
In order for this process to remain stationary, we need to ensure that $-1 < \phi < 1$, $Y_0 \sim \text{Nor}(0,1)$, and that the $\epsilon_i$'s are iid $\text{Nor}(0, 1 - \phi^2)$.
Unlike the MA(1) process, non-consecutive observations in the AR(1) process have non-zero correlation. Specifically, the covariance function between $Yi$ and $Y{i+k}$ is as follows:
The correlations start out large for consecutive observations and decrease as $k$ increases, but they never quite become zero; there is always some correlation between any two observations in the series.
If $\phi$ is close to one, observations in the series are highly positively correlated. Alternatively, if $\phi$ is close to zero, observations in the series are highly negatively correlated. If $\phi$ is close to zero, then the $Y_i$'s are nearly independent.
How do we generate observations from an AR(1) process? Let's start with $Y_0 \sim \text{Nor}(0,1)$ and $\epsilon_1 \sim \sqrt{1-\phi^2}\text{Nor}(0,1)$ to get $Y_1 = \phi Y_0 + \epsilon_1$. Then, we can generate $\epsilon_2 \sim \sqrt{1-\phi^2}\text{Nor}(0,1)$ to get $Y_2 = \phi Y_1 + \epsilon_2$, and so on.
Remember that:
So:
Here are the plots of three AR(1) processes, each parameterized with a different value of $\phi$.

ARMA(p,q) Process
The ARMA($p$,$q$) process is an obvious generalization of the MA(1) and AR(1) processes, which consists of a $p$th order AR process and a $q$th order MA process, which we will define as:
In the first sum, we can see the $p$ autoregressive components, and, in the second sum, we can see the $q$ moving average components.
We have to take care to choose the $\phi_j$'s and the $\theta_j$'s in such a way to ensure that the process doesn't blow up. In any event, ARMA($p$, $q$) processes are used in a variety of forecasting and modeling applications.
Exponential AR Process
An exponential autoregressive process, or EAR, is an autoregressive process that has exponential, not normal, noise. Here's the definition:
Here we need to ensure that $0 \leq \phi < 1$, $Y_0 \sim \text{Exp}(1)$, and the $\epsilon_i$'s are iid Exp(1) random variables.
Believe it or not, the EAR(1) has the same covariance function as the AR(1), except that the bounds of $\phi$ are different:
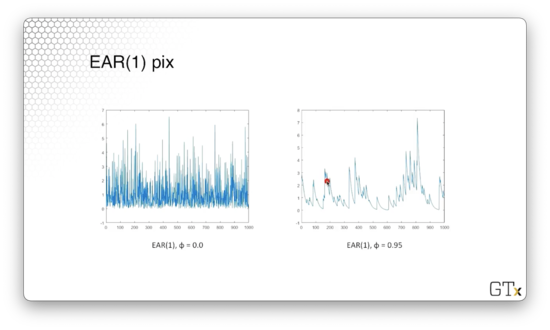
Let's look at a plot of an EAR(1) process with $\phi = 0$. These observations are iid exponential, and if we were to make a histogram of these observations, it would resemble the exponential distribution.
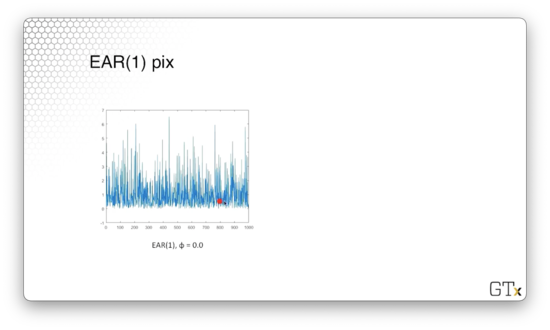
Here's a plot of an EAR(1) process with $\phi = 0.95$. We can see that when successive observations decrease, they appear to decrease exponentially. With probability $1 - \phi = 0.05$, they receive a jump from $\epsilon_i$, which causes the graph to shoot up.
Autoregressive Pareto - ARP
A random variable $X$ has the Pareto distribution with parameters $\lambda > 0$ and $\beta > 0$ if it has the cdf:
This distribution has a very fat tail. In other words, its pdf approaches zero (its cdf approaches one) much more slowly than the normal distribution.
To obtain the ARP process, let's first start off with a regular AR(1) process with normal noise:
Recall that we need to ensure that $-1 < \rho < 1$, $Y_0 \sim \text{Nor}(0,1)$, and that the $\epsilon_i$'s are iid $\text{Nor}(0, 1 - \rho^2)$. Note that that $Y_i$'s are marginally Nor(0,1), but they are correlated on the order of $\rho^{|k|}$.
Since the $Y_i$'s are standard normal random variables, we can plug them into their own cdf, $\Phi(\cdot)$ to obtain Unif(0,1) random variables: $U_i = \Phi(Y_i), i = 1,2,...,$. Since the $Y_i$'s are correlated, so are the $U_i$'s.
Now, we can feed the correlated $U_i$'s into the inverse of the Pareto cdf to obtain correlated Pareto observations:
DEMO
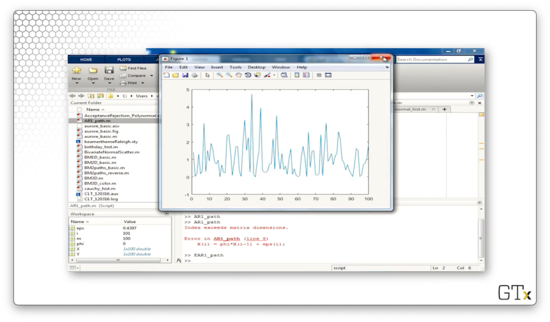
In this demo, we will implement an EAR(1) process in Matlab. Consider the following code:
We start out with phi equal to zero, so we are generating simple exponential observations. We initialize X(1) to exprnd(1,1), which is one Exp(1) observation. Then we iterate.
On each iteration, we set subsequent X(i) entries to phi*X(i-1) + (exprnd(1,1) * binornd(1,1-phi)). Notice the second term in this expression. This term represents adding exponential noise with probability phi. The binornd function returns zero with probability phi, zeroing out the noise, and returns one with probability 1-phi.
Let's see the plot.
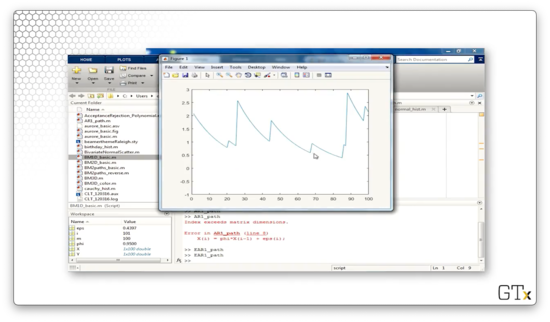
Now let's increase phi to 0.95 and look at the plot again. As we saw previously, we see what looks like exponential decay punctuated by random jumps.
Queueing (OPTIONAL)
In this lesson, we will discuss an easy way to generate random variables associated with queueing processes.
M/M/1
Let's consider a single-server queue with customers arriving according to a Poisson($\lambda$) process. As we know, the interarrival times are iid Exp($\lambda$), and the service times are iid Exp($\mu$). Customers potentially wait in a FIFO queue upon arrival, depending on the state of the server. In general, we require that $\mu > \lambda$; if customers don't get served faster than they arrive, the queue grows unbounded.
In terms of notation, we let $I_{i+1}$ denote the interrival between the $i$th and $(i+1)$st customer. We let $S_i$ be the $i$th customer's service time, and we let $W^Q_i$ denote the $i$th customer's wait before service.
Lindley Equations
Lindley gives a simple equation for generating a series of waiting times where we don't need to worry about the exponential assumptions. Here's how we generate the $(i+1)$st queue time:
This expression makes sense. If the $i$th customer waited a long time, we expect the $(i+1)$st customer to wait a long time. Similarly, if the $i$th customer has a long service time, we expect the $(i+1)$st customer to wait a long time. However, if the $(i+1)$st interarrival time is long, perhaps the system had time to clear out, and the $(i+1)$ customer might not have to wait so long. Of course, wait times cannot be negative.
We can express the total time in the system for customer $i$ as $Wi^Q + S_i$. Here's how we generate $W^Q{i+1}$:
Customer $i+1$ has to wait until customer $i$ clears out of the system, which occurs in $Wi - I{i+1}$ time. Then, customer $i+1$ must remain in the system for their service time, $S_{i+1}$.
Brownian Motion
In this lesson, we'll look at generating Brownian motion, as well as a few applications. Brownian motion is probably the most important stochastic process out there.
Brownian Motion
Robert Brown discovered Brownian motion when he looked at pollen under a microscope and noticed the grains moving around randomly. Brownian motion was analyzed rigorously by Einstein, who did a physics formulation of the process and subsequently won a Nobel prize for his work. Norbert Wiener establishes mathematical rigor for Brownian motion: Brownian motion is sometimes called a Wiener process.
Brownian motion is used everywhere, from financial analysis to queueing theory to chaos theory to statistics to many other operations research and industrial engineering domains.
The stochastic process, ${\mathcal{W}(t), t \geq 0 }$, is standard Brownian motion if:
$\mathcal{W}(0) = 0$
$\mathcal{W}(t) \sim \text{Nor}(0,t)$
${\mathcal{W}(t), t \geq 0 }$ has stationary and independent increments.
Let's talk about the first two points. A standard Brownian motion process always initializes at zero, and the distribution of the process, evaluated at any point, $t$, is Nor(0, $t$). This result means that a Brownian motion process has a correlation structure.
An increment describes how much the process changes between two points. For example, $\mathcal{W}(b) - \mathcal{W}(a)$ describes the increment from time $a$ to time $b$. If a process has stationary increments, then the distribution of how much the process changes over an interval from $t$ to $t + h$ only depends on the length of the interval, $h$.
We can recall our discussion of stationary increments from when we talked about arrivals. For example, if the number of customers arriving at a restaurant between 2 a.m and 5 a.m has the same distribution as the number of customers arriving between 12 p.m and 3 p.m, we would say that the customer arrival process has stationary increments.
Now let's talk about independent increments. A process has independent increments if, for $a < b < c < d$, $\mathcal{W}(d) - \mathcal{W}(c)$ is independent of $\mathcal{W}(b) - \mathcal{W}(a)$.
How do we get Brownian motion? Let's let $Y_1, Y_2,...,Y_n$ be any sequence of iid random variables with mean zero and variance one. Donsker's Central Limit Theorem says that:
Remember that $\overset{\text d}{\to}$ denotes convergence in distribution as $n$ gets big and $\lfloor \cdot \rfloor$ denotes the floor or "round down" function: $\lfloor 3.7 \rfloor = 3$.
When we learned the standard central limit theorem, $t$ was equal to one, and the $Y_i$'s converged to a Nor(0,1) random variable. Note that $\mathcal{W}(1) \sim \text{Nor}(0,1)$. As we can see, Donsker's central limit theorem is a generalization of the standard central limit theorem, as it works for all $t$. Not only that, but this central limit theorem also mimics the correlation structure of all the $\mathcal{W}$'s. Instead of converging to a single random variable, this sum converges to an entire stochastic process for arbitrary $t$.
Let's look at an easy way to construct Brownian motion. To construct $Y_i$'s that have mean zero and variance one, we can take a random walk. Let's take $Y_i = \pm 1$, each with probability $1/2$. Let's take $n$ of at least 100 observations. Then, let $t=1/n, 2/n, ...,n/n$ and calculate $\mathcal{W} (1/n), \mathcal{W} (2/n), ..., \mathcal{W} (n/n)$, according to the summation above. Another choice is to simply sample $Y_i \sim \text{Nor}(0,1)$.
Let's construct some Brownian motion. First, we pick some "large" value of $n$ and start with $\mathcal{W}(0)=0$. Then:
Miscellaneous Properties of Brownian Motion
As it turns out, Brownian motion is continuous everywhere but is differentiable nowhere.
The covariance between two points in a Brownian motion is the minimum of the two times: $\text{Cov}(\mathcal{W}(s), \mathcal{W}(t)) = \min(s,t)$. We can use this result to prove that the area under $\mathcal{W}(t)$ from zero to one is normal:
A Brownian bridge, $\mathcal{B}(t)$, is conditioned Brownian motion such that $\mathcal{W}(0) = \mathcal{W}(1) = 0$. Brownian bridges are useful in financial analysis. The covariance structure for a Brownian bridge is $\text{Cov}(\mathcal{B}(s), \mathcal{B}(t)) = \min(s,t) - st$. Finally, the area under $\mathcal{B}(t)$ from zero to one is normal:
Geometric Brownian Motion
Now let's talk about geometric Brownian motion, which is particularly useful in financial analysis. We can model a stock price, for example, with the following process:
Let's unpack some of these terms. Of course, $\mathcal{W}(t)$ is the Brownian motion, which provides the randomness in the stock price. The term $\sigma$ refers to the stock's volatility, and $\mu$ is related to the "drift" of the stock's price. Long story short: don't buy a stock unless it is drifting upward. The quantity $\mu - \sigma^2 / 2$ relates the stock's drift to its volatility, and we want this quantity to be positive. Finally, $S(0)$ is the initial price.
Additionally, we can use a geometric Brownian motion to estimate option prices. The simplest type of option is a European call option, which permits the owner to purchase the stock at a pre-agreed strike price, $k$, at pre-determined expiry date, $T$. The owner pays an up-front fee for the privilege to exercise this option.
Let's look at an example. Say that we believe that IBM will sell for $120 per share in a few months. Currently, it's selling for $100 per share. It would be nice to buy 1000 shares of IBM at $100 per share today, but perhaps we don't have $100,000 on hand to make that purchase. Instead, we can buy an option today, for maybe $1.50, that allows us to buy IBM at $105 per share in a few months. If IBM does go to $120 per share, we can exercise our option, instantaneously buying IBM for $105 and selling for $120, netting a $13.50 profit ($15 minus the option price, $1.50).
If the stock drops to, say, $95 per share, then we would choose simply not to exercise the option. Obviously, it doesn't make sense to buy IBM for $105 per share using the option when we can just go to the market and buy it for less.
The question then becomes: what is a fair price to pay for an option? The value, $V$ of an option is:
The expression $S(T) - k$ is the profit we make from exercising an option at time $T$, which we bought for $k$ dollars. Since we never consider taking a loss, we only consider the difference when it is positive: $S(T) - k^+ = \max{0,S(T) - k}$.
Instead of buying the option, we could have put the money we spent, $1.50, into a bank, where it would make interest. In purchasing the option, we have to pay a penalty of $e^{-rT}$, where $r$ is the "risk-free" interest rate that the government is currently guaranteeing.
We can calculate $V$ to determine what the option is worth. For example, if we determine that the option is worth $1.50, and we can buy it for $1.30, then perhaps we stand to make some profit.
Alternatively, we can use the option merely for an insurance policy. Southwest airlines bought options on fuel prices many years ago. The fuel prices went way up, and Southwest made a fortune because they could buy fuel at a much lower price.
To estimate the expected value of the option, we can run multiple simulation replications of $\mathcal{W}(t)$ and $(S(T) - k)^+$ and then take the sample average of all the $V_i$'s. All we need to do is select our favorite values of $r$, $\sigma$, $T$, and $k$, and we are off to the races.
Alternatively, we can just simulate the distribution of $S(T)$ directly. Since $\mathcal{W}(t) \sim \text{Nor}(0, t)$, we can use a lognormal distribution to simulate $S(T)$ directly. Furthermore, we can look up the answer directly using the Black-Sholes equation.
How to Win a Nobel Prize
Let $\phi(\cdot)$ and $\Phi(\cdot)$ denote the Nor(0,1) pdf and cdf respectively. Moreover, let's define a constant, $b$:
The Black-Sholes European call option value is:
DEMO
In this demo, we will generate some Brownian motion. Here's ten steps of Brownian motion in one dimension.
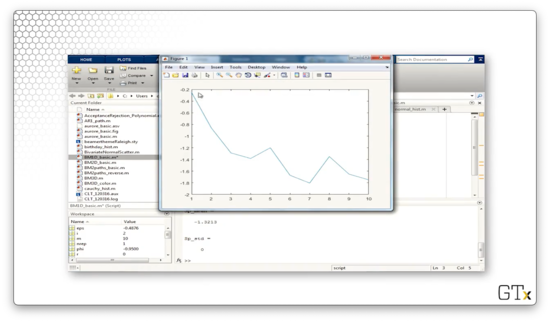
Here's another sample path.

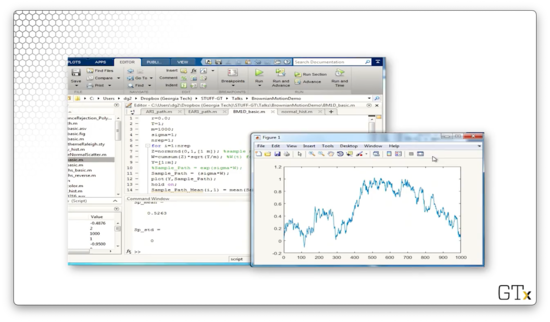
Let's take 1000 steps.
Let's generate ten steps of two-dimensional Brownian motion.
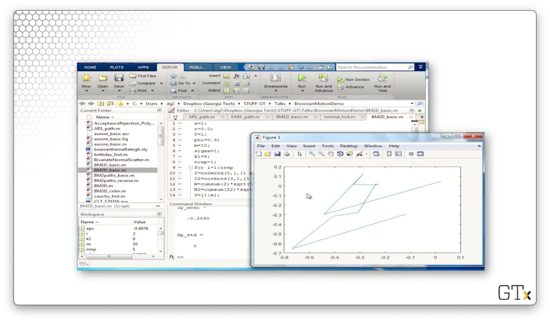
Here's 1000 steps.

Here's 10000 steps.

Finally, let's look at Brownian motion in three dimensions.

Last updated